안녕하세요. J4J입니다.
이번 포스팅은 kafka로 분산형 데이터 처리하기 마지막인 spring boot에 kafka consumer 사용 환경 설정하는 방법에 대해 적어보는 시간을 가져보려고 합니다.
이전 글
[SpringBoot] Kafka로 분산형 데이터 처리하기 (1) - Kafka란 무엇인가?
[SpringBoot] Kafka로 분산형 데이터 처리하기 (2) - Virtual Box에서 Kafka 설치하기
[SpringBoot] Kafka로 분산형 데이터 처리하기 (3) - Kafka에서 사용하는 명령어
[SpringBoot] Kafka로 분산형 데이터 처리하기 (4) - SpringBoot에 Kafka Producer 사용 환경 설정
Kafka Consumer 란?
이전 글들에서 적어둔 것처럼 kafka consumer는 kafka producer에 의해 partition에 저장되어 있는 레코드를 전달받는 주체를 의미합니다.
즉, producer에 의해 저장되어 있는 레코드 데이터들을 전달 받아 레코드 정보를 이용한 비즈니스 로직을 정의하는 시작점이 됩니다.
조금 더 쉽게 이해를 해보자면, spring을 이용하여 개발하는 대부분의 개발자 분들이 알 수 있는 api가 consumer와 이름만 다르지 역할은 유사하다고 볼 수 있습니다.
많은 분들이 알 듯이 api에서는 controller 기반으로 어떤 endpoint 경로에 어떤 paramter 및 body 데이터를 필요로 하는 객체의 형태로 전달받아 service, repository까지 연결되어 비즈니스 처리를 위한 통로 역할을 하게 됩니다.
consumer도 api와 유사한 역할을 하게 됩니다.
api에서는 요청하는 주체가 client가 되어 api를 호출하지만, consumer에서는 kafka의 topic에 consumer에서 소비해야 하는 메세지 정보가 담겨 있는 경우 consumer의 동작이 실행됩니다.
또한, consumer에서도 api를 정의할 때와 유사하게 메세지를 소비할 때 필요로 하는 객체의 형태를 정의하고 데이터를 전달받아 service, repository까지 연결하는 비즈니스를 정의할 수도 있습니다.
그리고 중요한 사항 중 하나는 1개의 topic에 1개의 consumer만 연결되는 것이 아닙니다.
1개의 topic을 바라보고 있는 consumer는 여러 개가 될 수 있고, 다른 말로는 partition에 레코드 정보가 쌓이게 되는 경우 동일한 topic을 바라보고 있는 모든 consumer에 동일한 레코드 정보가 전달되는 것을 의미합니다.
이런 consumer의 동작은 scale out 되어있는 서버 구조에서 잘못된 설정을 하게 된다면 1개만 소비되어야 하는 메세지가 scale out 되어 있는 모든 애플리케이션에서 각각 소비될 수 있습니다.
그러면 생각한 것과 달리 반복된 과도한 비즈니스 처리가 발생하게 되어 예상하지 못한 결과를 야기하게 됩니다.
해당 설정과 관련되어서도 아래에서 더 다뤄보도록 하겠습니다.
SpringBoot에서 Kafka Consumer 사용 환경 설정 방법
[ 1. dependency 설정 ]
// build.gradle
dependencies {
// kafka
implementation 'org.springframework.kafka:spring-kafka'
}
[ 2. properties 설정 ]
kafka consumer 동작을 위한 properties 설정은 application.yml 파일을 통해 할 수 있습니다.
아마도 일반적인 상황에서는 하지 않겠지만 해당 방법 외에도 클래스 파일로써 설정이 필요하다면 커스텀하여 @Configuration을 통해 등록하는 방법도 존재합니다.
kafka server 설정부터 시작하여 serializer 등 필요한 설정들에 대해 yml 파일에 다음과 같이 정의 해볼 수 있습니다.
spring:
kafka:
# kafka consumer 설정
consumer:
value-deserializer: org.apache.kafka.common.serialization.StringSerializer # value 직렬화 방법 설정
key-deserializer: org.apache.kafka.common.serialization.StringSerializer # key 직렬화 방법 설정
bootstrap-servers: ubuntu:9092 # kafka cluster server (이곳에서는 virtual box 연결)
auto-offset-reset: earliest # offset 설정이 없는 경우 topic의 처음부터 읽기 시작
group-id: consumer-group # consumer group id 설정
[ 3. listener 등록 ]
partition에 저장되어 있는 특정 topic에 대한 레코드를 전달 받기 위해 listener 설정을 해주시면 됩니다.
listener는 consumer가 메세지를 전달받았을 때 전달된 데이터를 이용하여 비즈니스를 정의하는 곳입니다.
listener를 등록할 때는 topic 정보를 설정할 수 있고, listener가 등록되어 있는 상황에서 애플리케이션이 동작하고 있다면 topic에서 관리하는 메시지 정보를 전달받을 수 있습니다.
이전 글에서 사용했던 topic 정보를 이용하기 위해 다음과 같이 작성해보겠습니다.
package com.jforj.kafkaconsumer.listener;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class KafkaTopicListener {
private final ObjectMapper objectMapper;
@KafkaListener(topics = "my-topic")
public void receive(String message) throws JsonProcessingException {
Record record = objectMapper.readValue(message, new TypeReference<>() {
});
System.out.println("my-topic message consume.");
System.out.println("name= " + record.getName());
System.out.println("height= " + record.getHeight());
}
@Getter
private static class Record {
private String name;
private Long height;
}
}
[ 4. 테스트 ]
이전에 producer 처리를 위해 만들어 둔 api server의 port를 8081로 변경한 뒤 실행하고, 위에서 작성한 consumer는 8080 port를 이용하여 실행해 보겠습니다.
그리고 다음과 같이 api를 호출하여 producer에 의해 레코드 정보가 kafka에 전달하면 consumer에서 레코드 정보를 가져와 소비하면서 애플리케이션 로그에 출력 값이 생기는 것을 확인할 수 있습니다.


Consumer Group
consumer group은 consumer가 partition에 저장되어 있는 레코드 정보를 소비하려고 할 때 같은 group 안에 있는 consumer 들 중 1곳에서만 소비되게 할 수 있도록 도와줍니다.
즉, 위에서 얘기한 것처럼 1개의 topic을 바라보는 consumer 들은 여러 개가 될 수 있을 텐데 이런 환경에서 1개의 메시지가 모든 consumer에서 소비되지 않고 1개의 consumer에서만 소비될 수 있습니다.
spring을 통해 consumer 환경 설정을 할 때는 위의 properties 설정과 같이 consumer.group-id를 설정하여 적용할 수 있습니다.
또한, spring에서는 group-id를 설정하지 않는 경우 애플리케이션을 실행할 때 에러를 발생시키기 때문에 필수 적용 값이 될 수 있습니다.
그리고 properties에 설정하는 경우 해당 어플리케이션 내부에 있는 모든 consumer가 동일한 group-id 값이 적용됩니다.
즉, default 값으로 group-id가 적용된다는 뜻인데 상황에 따라 consumer 마다 서로 다른 group-id를 설정하고 싶은 경우가 발생할 수 있고 설정을 원한다면 @KafkaListener에 다음과 같이 consumer 별로 커스터마이징 하여 적용할 수 있습니다.
public class KafkaTopicListener {
@KafkaListener(topics = "my-topic", groupId = "my-topic-consumer-group") // listener 에서만 사용되는 group id 설정
public void receive(String message) throws JsonProcessingException {
...
}
}
consumer group의 또 다른 대표적인 기능으로는 offset 정보를 관리하는 것이 있습니다.
예를 들어 topic에 10개의 레코드가 쌓여 있고 consumer-group에 속하는 consumer가 10개의 레코드를 모두 소비한 상태에서 consumer를 동작시키는 서버가 갑자기 문제가 발생한다고 가정하겠습니다.
서버가 복구되는 동안 topic에 5개의 레코드가 더 쌓이게 되어 15개의 레코드가 쌓이게 되었고, 이후로 consumer 서버가 복구되면 서버에 문제가 발생하 동안 쌓인 5개의 레코드 정보에 대해서 consumer는 소비할 필요가 있습니다.
이와 같은 상황에서 consumer group은 해당 topic에서 10개 까지 해당되는 정보를 읽었다는 offset 값을 소유하고 있게 됩니다.
결국 consumer 서버가 복구되어 consumer가 동작할 수 있는 상태가 된다면 저장되어 있는 offset 값을 이용하여 메시지를 소비하지 않는 레코드부터 시작하여 순차적으로 메세지를 소비하게 됩니다.
해당 방식이 올바르게 동작하는지 확인하기 위해 기존에 사용되던 group id 정보를 동일하게 설정한 상태에서 consumer 애플리케이션을 종료해 보겠습니다.
그리고 종료되어 있는 동안 producer 처리를 도와주는 api를 다음과 같이 값을 달리 한 상태로 3번 호출해 보겠습니다.
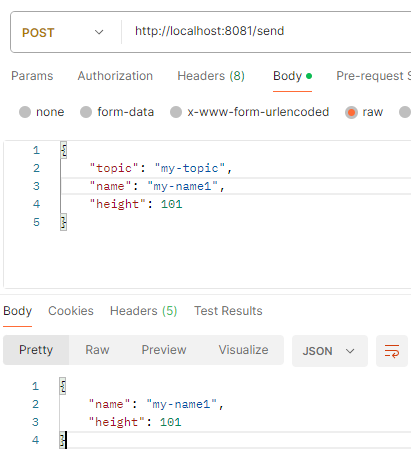
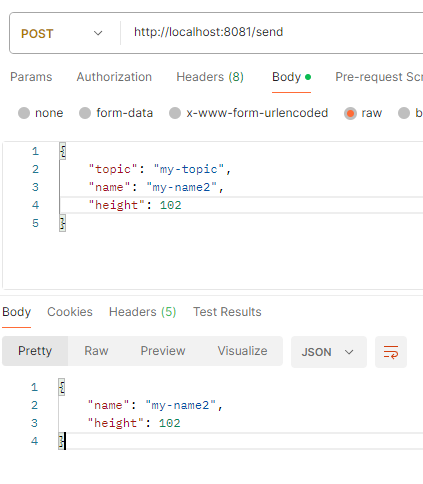

topic에 메시지를 쌓았다면 consumer 처리를 수행하는 애플리케이션을 다시 동작해 보겠습니다.
그러면 기존에 소비했던 메시지는 제외하고, 소비하지 못했던 메세지 정보부터 시작하여 정보를 가져와서 메시지를 소비하는 것을 확인할 수 있습니다.

이상으로 kafka로 분산형 데이터 처리하기 마지막인 spring boot에 kafka consumer 사용 환경 설정에 대해 간단하게 알아보는 시간이었습니다.
읽어주셔서 감사합니다.
'Spring > SpringBoot' 카테고리의 다른 글
| Kubernetes에서 Spring 애플리케이션 Metric 수집하여 모니터링하기, Prometheus & Grafana 연동 (0) | 2025.09.15 |
|---|---|
| 애플리케이션 모니터링을 위한 Spring Boot Actuator, 개념 정리와 구성 가이드 (1) | 2025.09.10 |
| [SpringBoot] Kafka로 분산형 데이터 처리하기 (4) - SpringBoot에 Kafka Producer 사용 환경 설정 (0) | 2024.09.17 |
| [SpringBoot] Kafka로 분산형 데이터 처리하기 (3) - Kafka에서 사용하는 명령어 (0) | 2024.09.03 |
| [SpringBoot] Kafka로 분산형 데이터 처리하기 (2) - Virtual Box에서 Kafka 설치하기 (8) | 2024.08.25 |


댓글