안녕하세요. J4J입니다.
이번 포스팅은 jpa로 대용량 데이터 처리하는 방법에 대해 적어보는 시간을 가져보려고 합니다.
Insert
jpa로 데이터를 insert 하면서 가장 많이 사용되는 것은 jpa repository가 제공하는 save 메서드입니다.
또한 saveAll이라는 메서드도 존재합니다.
저도 옛날부터 save와 saveAll에 대해 오해의 소지가 있었던 것 중 하나가, saveAll을 사용해야 save를 사용하는 것보다 더 빠른 속도로 데이터 처리를 해준다는 것입니다.
사실, saveAll을 쓴다고 save를 사용하는 것보다 더 빠른 속도로 데이터 처리를 하지는 않습니다.
왜냐하면 saveAll 내부를 살펴보면 다음과 같이 단순히 save를 반복 처리해 주는 편의 기능 정도로만 담겨 있기 때문입니다.
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, ENTITIES_MUST_NOT_BE_NULL);
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
그렇기 때문에 혹시나 저처럼 saveAll에 대한 오해를 하고 있는 분이 계시다면 다시 한번 효과적인 대용량 데이터 insert 방식에 대해 고민해봐야 합니다.
그리고 제가 지금까지 사용해 봤던 방식에 대해서 간단하게 정리해 보겠습니다.
[ 1. jdbc batch 처리 ]
대용량 데이터를 insert 할 때 적용 해볼 수 있는 가장 대표적인 것은 jdbc batch 설정을 하는 것입니다.
보통 save를 통해 데이터를 insert 하게 되면 flush 처리가 발생될 때 데이터 생성을 위한 query들이 데이터베이스에 전달됩니다.
이때, batch 설정을 하지 않으면 save 호출마다 데이터베이스와 매번 네트워크 통신이 이루어집니다.
즉, 1000개의 save 메서드가 호출되었다면 최소 데이터베이스와 1000번의 통신이 이루어지는 것입니다.
jdbc batch라고 하는 것은 여러 개의 query들을 하나의 묶음으로 만들어 일괄적으로 데이터베이스 요청하는 것을 말합니다.
그렇기 때문에 설정에 따라 다른 부분이 있지만, 만약 batch를 사용하게 된다면 1000개의 save 메서드가 호출되었을 때 1번만 데이터베이스와 네트워크 통신이 이루어지는 것도 가능하게 됩니다.
네트워크 비용이 굉장히 많이 줄어들기 때문에 더 빠른 속도로 데이터 insert 하는 작업을 수행할 수 있도록 도와줍니다.
jdbc batch를 사용하는 설정은 굉장히 간단합니다.
hibernate 기반으로 설정이 필요하며, 다음과 같이 resource 파일을 작성해 주시면 됩니다.
// build.gradle
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100 # 한 번에 전달되는 query 개수 설정
order_inserts: true # insert sql 정렬 (동일 query끼리 묶기 위해 사용)
제가 이 단순한 설정을 통해 몇 만 건의 데이터까지 문제없이 일괄 insert 처리를 수행하고 있습니다.
물론, 속도 또한 굉장히 빠르고요.
다만 이 정도의 선에서는 문제가 발생하지 않겠지만, 이 보다 더 많은 몇 십만 건 이상의 데이터들을 처리하기 위해서는 엔티티 관리 비용이 드는 jpa를 사용하는 것보다 jdbc bulk insert와 같이 native 한 방식이 사용되는 것이 권장됩니다.
[ 2. persistable 설정 ]
persistable은 entity가 신규인지 기존에 존재하던 값인지를 판단합니다.
그리고 이런 판단은 entity의 @Id 설정이 담긴 필드를 보고 자동으로 인지가 됩니다.
- @Id 설정한 필드 값이 null인 경우 → 신규 데이터 (persist 처리)
- @Id 설정한 필드 값이 null이 아닌 경우 → 존재하던 데이터 (merge 처리)
한 번씩 신규 데이터를 insert를 하려고 save 메서드를 호출할 때마다 insert query가 호출되기 전 select query가 호출되는 경험을 겪어 보신 적이 있을 겁니다.
이때, select query가 발생한 이유가 persistable 때문입니다.
이런 상황을 겪은 데이터들은 pk 필드가 auto_increment 등의 설정이 되어 있지 않기 때문에 애플리케이션 내부에서 @Id에 해당하는 필드 값을 직접 설정한 경우들입니다.
entity의 @Id 값에 데이터가 담겨 있기 때문에 jpa는 다음과 같이 동작이 이루어집니다.
- 어? @Id 값에 데이터가 존재하니까 merge를 위해 데이터베이스의 데이터를 조회해 보자! → select query 발생
- 어라? @Id 값에 해당하는 데이터가 없어! 그냥 insert 처리를 하면 되겠다! → insert query 발생
여기서도 1000개의 데이터를 insert 해야 된다고 가정할 때 위와 같은 상황이라면 불 필요한 1000개의 select query가 발생하는 결과를 만듭니다.
insert query만 하더라도 많은 양의 query를 처리해야 하는데, 불 필요한 select query의 동작 때문에 처리되어야 하는 query의 개수가 2배 증가됩니다.
이를 해결하기 위해 개발자가 직접 persist/merge 중 어떤 것을 수행해야 하는지 알려줌으로써 select query를 호출하지 않게 할 수 있습니다.
예시로 다음과 같은 entity가 있다고 가정해 보겠습니다.
public class StringTableEntity {
@Id
private String id;
private String name;
private LocalDateTime createDate;
@PrePersist
public void prePersist() {
this.createDate = LocalDateTime.now();
}
}
이 entity를 insert 하기 위해 id 값을 직접 넣어주고 save 메서드를 실행하면 다음과 같이 select와 insert가 동시 발생합니다.

이 상황에서 persistable 설정을 추가하기 위해 entity를 다음과 같이 변경해 줍니다.
public class StringTableEntity implements Persistable<String> {
@Id
private String id;
private String name;
private LocalDateTime createDate;
@PrePersist
public void prePersist() {
this.createDate = LocalDateTime.now();
}
@Override
public boolean isNew() {
return this.createDate == null;
}
}
isNew는 entity가 데이터를 조회하는 행위 없이 새로운 entity 인지를 판단하는 데 사용하며, createDate 값을 prePersist 등을 이용하여 설정한다면 isNew를 판단하는 요소로 createDate를 사용하기 가장 적합합니다.
그렇지 않다면 @Transient 설정을 통해 isNew 필드를 별도 관리하고, 개발자가 판단하여 isNew 값을 변경해 주는 작업을 수행해야 합니다.
올바르게 persistable 설정이 되었다면 데이터 insert 할 때 select query가 호출되지 않고 insert query만 호출되는 것을 볼 수 있습니다.
Update
[ 1. jdbc batch 처리 ]
update를 할 때도 jdbc batch 처리를 통해 도움을 많이 받을 수 있습니다.
insert와 마찬 가지로 save 메서드마다 데이터베이스와 매번 네트워크 통신을 수행하지 않고, update 해야 되는 query 들을 묶어서 일괄적으로 데이터베이스에 전달을 할 수 있습니다.
사실 insert 쪽에서 얘기를 안 한 것 중 하나가 batch 처리를 위해서는 동일한 sql 들끼리 모여 있을 때만 query들을 묶어서 전달하게 됩니다.
여기서 말하는 동일한 sql이란, 동일한 entity를 가지고 여러 개의 query를 호출한다고 하더라도 파라미터 정보들을 제외한 query가 동일해야 한다는 것입니다.
예를 들면,
- update table set value=? where id=?
- update table set value=? name=? where id=?
의 형태는 서로 다른 query라고 얘기할 수 있습니다.
이와 같이 batch 효과를 극대화하기 위해서 hibernate의 order 설정을 필수적으로 해줘야 합니다.
update에서도 jdbc batch 처리를 위한 설정은 굉장히 간단합니다.
다음과 같이 설정을 하게 된다면 insert처럼 일괄적으로 update가 수행되는 것을 경험할 수 있습니다.
// build.gradle
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100 # 한 번에 전달되는 query 개수 설정
order_updates: true # update sql 정렬 (동일 query끼리 묶기 위해 사용)
[ 2. bulk update ]
bulk update는 1개의 update query로 여러 개의 데이터를 한 번에 수정하는 대용량 update 방식입니다.
bulk update가 필요한 상황은 다음과 같습니다.
- 모든 데이터의 name 필드를 1개의 값으로 일괄 변경
- 생성된 시간이 1년 안에 포함되는 모든 데이터들의 target 필드를 true로 일괄 변경
- 등등..
만약, 이런 케이스의 데이터 처리를 jpa로 한다면 다음과 같은 상황이 발생하게 됩니다.
- 조건에 포함되는 대용량 데이터를 모두 select
- 조회된 모든 데이터에 대해 update query 수행
bulk update를 이용한다면 update query 1개로 모든 데이터에 적용할 수 있지만, jpa를 그대로 이용한다면 데이터 조회부터 시작하여 update 하는 query의 비용이 굉장히 많이 발생하게 됩니다.
그래서 어떤 update를 수행해야 되는지에 따라 bulk update를 적용하는 것은 굉장히 이상적인 방법이 됩니다.
bulk update를 적용하는 가장 쉬운 방법은 JPQL을 사용하는 것입니다.
다음과 같이 jpa repository에 bulk update를 위한 JPQL을 정의하여 사용해 볼 수 있습니다.
public interface StringTableJpaRepository extends JpaRepository<StringTableEntity, String> {
@Modifying
@Query("update StringTableEntity s set s.name = :name")
void updateAllName(String name);
}
그다음은 querydsl 같은 것을 활용하여 적용할 수도 있습니다.
JPQL의 동작과 유사하게 다음과 같이 사용한다면 이 또한 bulk update를 하는 방법이 될 수 있습니다.
jpaQueryFactory
.update(QStringTableEntity.stringTableEntity)
.set(QStringTableEntity.stringTableEntity.name, name)
.execute();
bulk update 할 때 가장 중요한 것 중 하나는 영속성 컨텍스트에는 bulk update가 수행된 것이 반영되지 않는다는 것입니다.
그래서 entity manager의 clear 메서드 등을 활용하여 영속성에서 관리되고 있는 모든 데이터들을 삭제하고, bulk update가 적용된 데이터로 다시 조회되어 비즈니스 처리가 될 수 있도록 세부적인 작업이 필요합니다.
만약 이를 고려하지 않고 bulk update를 사용한다면, 의도하지 않은 기능 동작이 발생하기 때문에 오히려 장애를 발생하는 요인이 될 수 있으니 조심해야 합니다.
Delete
[1. jdbc batch 처리 ]
delete도 insert, update와 동일하게 batch를 기반으로 삭제 처리가 수행될 수 있습니다.
다만, delete는 삭제하는 방식이 다음과 같이 대부분 동일한 방식으로 사용되기 때문에 insert, update처럼 order 설정을 따로 제공해주지 않습니다.
jpaRepository.delete(entity); -- (1)
jpaRepository.deleteById(id); -- (2)
그래서 대용량의 delete 처리를 batch 기반으로 수행할 때는 다음과 같은 방식만 고려되면 됩니다.
- 동일한 유형의 entity들끼리 묶어서 삭제하기 (서로 다른 entity를 번갈아가며 삭제하지 않기)
- 동일한 삭제 타입을 묶어서 사용하기 (delete만 모아서 사용하거나 deleteById만 모아서 사용하거나 등등)
또한 batch를 적용하기 위해서는 insert, update와 같이 다음처럼 jdbc batch 설정이 당연히 이루어져야 합니다.
// application.yml
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100 # 한 번에 전달되는 query 개수 설정
[ 2. bulk delete ]
delete도 update와 동일하게 다음과 같이 bulk 기반으로 삭제하는 경우가 필요합니다.
- name 필드에 특정 문자열이 들어간 모든 데이터를 삭제
- 수정된 지 1년이 지난 데이터들은 일괄 삭제
- 등등..
이런 경우에 대해 데이터 삭제를 jpa만 이용한다면 update처럼 많은 수의 select, delete query가 동작하는 결과가 만들어집니다.
그래서 update와 동일하게 1개의 query만을 이용하여 bulk 처리를 하게 된다면 효율적인 삭제 처리를 할 수 있게 됩니다.
bulk delete를 하는 방법도 update처럼 JPQL, querydsl 등을 이용하여 적용할 수 있습니다.
간단하게 예시 코드를 작성해 보면 다음과 같습니다.
// JPQL -- (1)
public interface StringTableJpaRepository extends JpaRepository<StringTableEntity, String> {
@Modifying
@Query("delete from StringTableEntity s where s.name like :name")
void deleteAllName(String name);
}
// querydsl -- (2)
jpaQueryFactory
.delete(QStringTableEntity.stringTableEntity)
.where(QStringTableEntity.stringTableEntity.name.containsIgnoreCase("name"))
.execute();
하지만 여기서도 중요한 것은 bulk delete도 영속성 컨텍스트에 반영되지 않습니다.
그래서 bulk delete 이후 entity와 관련된 비즈니스가 존재한다면 영속성 컨텍스트를 비운 뒤 비즈니스 처리를 하는 것을 권장합니다.
[ 3. delete 사용 ]
위에서 얘기한 것처럼 삭제를 할 때 delete, deleteById 등의 메서드가 사용됩니다.
이 중 delete를 이용한 삭제를 하는 것을 권장합니다.
왜냐하면 deleteById의 경우 삭제를 하기 전 select query를 호출한 뒤 delete 처리를 수행하기 때문입니다.
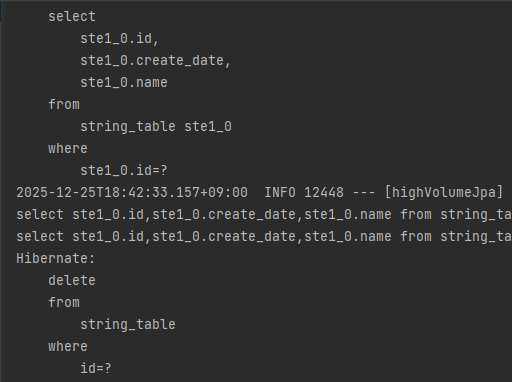
물론 delete를 사용하기 위한 전제조건이 존재합니다.
바로, 삭제되어야 하는 entity가 어디선가 조회되어 있어야 한다는 것입니다.
그래서 만약 삭제하기 전 entity를 조회한 적이 없다면 delete를 사용하나 deleteById를 사용하나 동작은 동일하게 됩니다.
하지만 삭제하기 전 비즈니스 처리를 위해 조회되어 있는 entity가 존재한다면, 해당 entity를 이용하여 바로 삭제 처리하는 것이 select query 비용을 감소시킵니다.
그러므로 조회된 entity 데이터가 이미 있는 경우에는 다음의 방식을 사용하여 삭제 처리하는 것을 권장합니다.
jpaRepository.delete(entity); -- (1)
jpaRepository.deleteAll(entities); -- (2)
이상으로 jpa로 대용량 데이터 처리하는 방법에 대해 간단하게 알아보는 시간이었습니다.
읽어주셔서 감사합니다.
'Spring > SpringBoot' 카테고리의 다른 글
| JPA 대용량 데이터 페이징, Offset보다 Keyset을 선택해야 하는 이유 (1) | 2025.12.30 |
|---|---|
| WebClient 도입기, 공통 설정 및 non-blocking과 MVC 사이의 현실적인 타협 (1) | 2025.12.17 |
| RestTemplate 말고 이거 사용하세요, RestClient 입문 가이드 (0) | 2025.12.12 |
| Micrometer Tracing으로 Spring 애플리케이션 분산 트레이싱하기 (3) | 2025.09.29 |
| Kubernetes에서 Spring 애플리케이션 Metric 수집하여 모니터링하기, Prometheus & Grafana 연동 (0) | 2025.09.15 |
댓글